Le système d’orchestration de conteneur est l’emplacement sur lequel la prochaine action est susceptible d’être en mouvement vers la construction → l’Expédition →l’Exécution des conteneurs à l’échelle. La liste des logiciels qui fournissent actuellement une solution pour cela sont Kubernetes, Docker Swarm, Apache Mesos et autres.
Ce tutoriel va parcourir le nouveau mode Docker Swarm, sur lequel le support d’orchestration de conteneur a été intégré dans le jeu d’outils Docker lui-même.
Cet article représente des apprentissages personnels et explore le mode Docker Swarm.
Pourquoi vouloir un système d’orchestration de conteneur ?
Pour faire simple, imaginez que vous deviez exécuter des centaines de conteneurs. Vous pouvez facilement voir que s’ils s’exécutent dans un mode distribué, il existe plusieurs fonctionnalités dont vous aurez besoin d’un point de vue de la gestion afin de vous assurer que le cluster est opérationnel, sain et plus.
La plupart de ces fonctionnalités indispensables comprennent :
- Les bilans de santé sur les conteneurs
- Le lancement d’un ensemble fixe de conteneurs pour une image Docker particulière
- La mise à l’échelle du nombre de conteneurs de haut en bas en fonction du chargement
- L’exécution de la mise à jour continue du logiciel à travers les conteneurs
- et plus…
Vous découvrirez comment faire la plupart de ces tâches en utilisant Docker Swarm. La documentation de Docker et le tutoriel pour essayer le mode Swarm ont été excellents.
Les conditions pré-requises :
- Vous devez connaitre les commandes Docker de base
- Vous devez avoir Docker Toolbox installé sur votre système
- Vous devez avoir au moins la version Docker 1.12
Créer des machines Docker
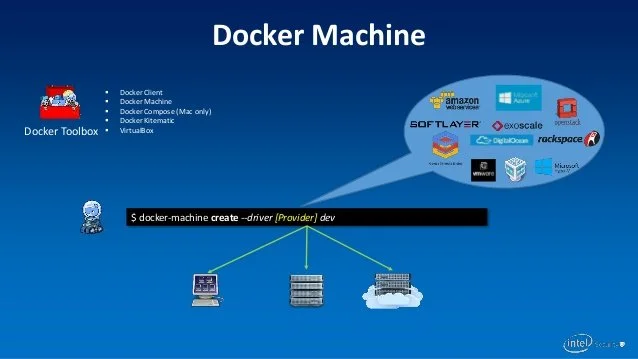
La première étape consiste à créer un ensemble de machines Docker qui serviront de nœuds dans votre Docker Swarm. Vous allez créer 6 Docker Machines, où l’un d’entre eux agira en tant que manager (Leader) et les autres seront des nœuds de travail. Vous pouvez créer moins de machines selon vos besoins.
On utilise la commande standard pour créer une Machine Docker nommé manager1 comme indiqué ci-dessous :
docker-machine create –driver hyperv manager1
Gardez à l’esprit que c’est fait sur Windows 10, qui utilise le manager Hyper-V natif, c’est pourquoi on utilise ce pilote. Si vous utilisez la boîte à outils Docker avec Virtual Box, cela ressemblerait à ceci :
docker-machine create –driver virtualbox manager1
De même, créez les autres nœuds de mots. Dans ce cas-ci, comme mentionné, il faut créer 5 autres nœuds de travail.
Après la création, il est conseillé de lancer la commande docker-machine ls pour vérifier l’état de toutes les machines Docker (sans oublier le PILOTE.)
NAME DRIVER URL STATE
manager1 hyperv tcp://192.168.1.8:2376 Running
worker1 hyperv tcp://192.168.1.9:2376 Running
worker2 hyperv tcp://192.168.1.10:2376 Running
worker3 hyperv tcp://192.168.1.11:2376 Running
worker4 hyperv tcp://192.168.1.12:2376 Running
worker5 hyperv tcp://192.168.1.13:2376 Running
Notez l’adresse IP du manager1, puisque vous en aurez besoin. Vous pouvez l’appeler MANAGER_IP plus tard dans le texte.
La méthode pour obtenir l’adresse IP de la machine manager1 est la suivante :
$docker-machine ip manager1 192.168.1.8
Vous devriez être à l’aise pour faire un SSH dans l’une des machines Docker. Vous en aurez besoin car vous exécuterez principalement les commandes du docker depuis la session SSH vers cette machine.
Gardez à l’esprit qu’en utilisant l’utilitaire de la machine docker, vous pouvez utiliser SSH sur l’une des machines comme suit :
docker-machine ssh <nom-machine>
À titre d’exemple, voici mon SSH dans la machine docker manager1 :
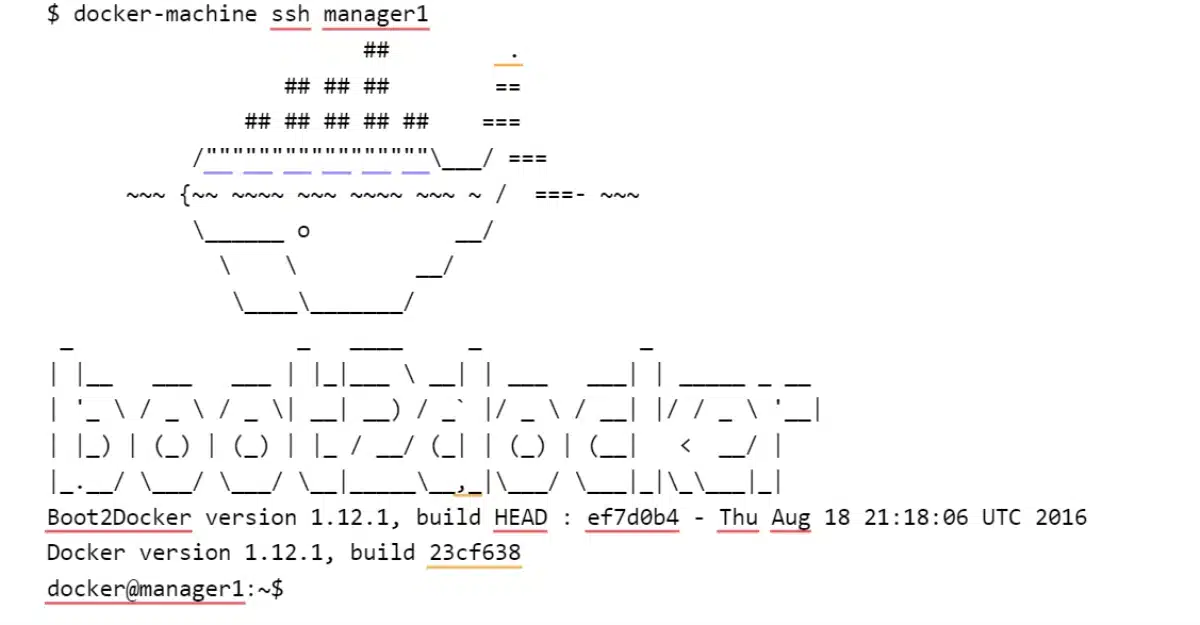
Votre cluster Swarm
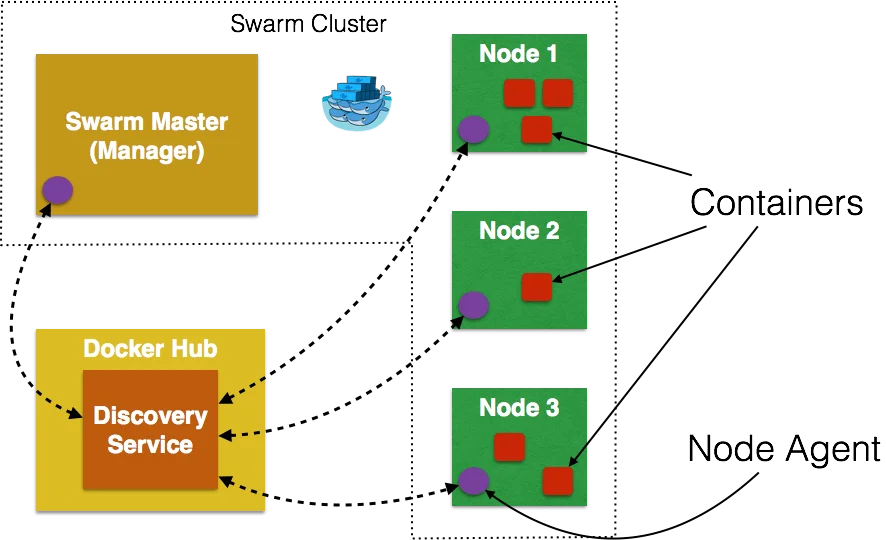
Maintenant que vos machines sont configurées, vous allez procéder à la configuration de Swarm.
La première chose à faire c’est d’initialiser Swarm. Vous allez faire un SSH dans la machine manager1 et initialiser Swarm là-dedans.
$ docker-machine ssh manager1
Cela va initialiser la session SSH et vous devriez être à l’invite comme indiqué ci-dessous :
Effectuez les étapes suivantes :
$ docker swarm init –advertise-addr MANAGER_IP
Au niveau de la machine, ça ressemble à ceci :
docker@manager1:~$ docker swarm init — advertise-addr 192.168.1.8 Swarm initialized: current node (5oof62fetd4gry7o09jd9e0kf) is now a manager.
Pour ajouter un travailleur à cet swarm, exécutez la commande suivante :
docker swarm join \ — token SWMTKN-1–5mgyf6ehuc5pfbmar00njd3oxv8nmjhteejaald3yzbef7osl1-ad7b1k8k3bl3aa3k3q13zivqd \ 192.168.1.8:2377
Pour ajouter un manager à ce swarm, lancez :
docker swarm join-token manager
Suivez les instructions.
docker@manager1:~$
Génial !
Vous remarquerez également que la sortie mentionne la commande de jointure docker swarm à utiliser dans le cas où vous souhaitez qu’un autre nœud se joigne en tant que travailleur.
Gardez à l’esprit que vous pouvez joindre un nœud en tant que travailleur ou en tant que manager. À tout moment, il n’y a qu’un seul LEADER et les autres nœuds du manager seront utilisés en tant que sauvegarde au cas où le LEADER actuel se désengagerait.
À ce stade, vous pouvez voir le statut de votre Swarm en entrant la commande suivante, comme indiqué ci-dessous :
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
5oof62fetd..* manager1 Ready Active Leader
Cela montre qu’il n’existe qu’un seul nœud maintenant, c’est-à-dire manager1 et qu’il a la valeur de Leader pour la colonne MANAGER.
Restez dans la même session SSH pour manager1.
Rejoindre en tant que travailleur de Node
Pour savoir quelle commande docker swarm doit être utilisée pour se connecter en tant que nœud, vous devez utiliser la commande jeton de jointure <rôle>.
Pour connaître la commande de jointure d’un travailleur, exécutez la commande suivante :
docker@manager1:~$ docker swarm join-token worker
Pour ajouter un travailleur à ce swarm, exécutez la commande suivante :
docker swarm join \
— token SWMTKN-1–5mgyf6ehuc5pfbmar00njd3oxv8nmjhteejaald3yzbef7osl1-ad7b1k8k3bl3aa3k3q13zivqd \
192.168.1.8:2377
docker@manager1:~$
Rejoindre en tant que manager de Node
Pour connaître la commande de jointure d’un manager, exécutez la commande suivante :
docker swarm join \
— token SWMTKN-1–5mgyf6ehuc5pfbmar00njd3oxv8nmjhteejaald3yzbef7osl1-ad7b1k8k3bl3aa3k3q13zivqd \
192.168.1.8:2377
docker@manager1:~$
Notez dans les deux cas ci-dessus que vous avez reçu un jeton et qu’il rejoint le nœud manager (vous pourrez identifier que l’adresse IP est identique à l’adresse MANAGER_IP).
Gardez-le SSH sur manager1 ouvert. Lancez d’autres terminaux de commande pour travailler avec d’autres machines dockers.
Ajoutez des nœuds de travail à votre Swarm
Maintenant que vous savez comment vérifier la commande pour rejoindre en tant que Worker, vous pouvez l’utiliser pour faire un SSH dans chacune des machines Docker, puis déclencher la commande de jointure correspondante.
Dans ce cas-ci, il y a 5 machines Worker (Worker1/2/3/4/5). Pour la première machine Docker Worker1, on fait ce qui suit :
- SSH dans la machine Worker1, c’est-à-dire docker-machine ssh Worker1
- Ensuite, lancez la commande correspondante que vous avez obtenu en tant que travailleur. Dans ce cas-ci, la sortie est indiquée ci-dessous :
docker@worker1:~$ docker swarm join \
— token SWMTKN-1–5mgyf6ehuc5pfbmar00njd3oxv8nmjhteejaald3yzbef7osl1-ad7b1k8k3bl3aa3k3q13zivqd \
192.168.1.8:2377
/Ce noeud a rejoint un swarm en tant que travailleur.
docker@worker1:~$
Faites la même chose en lançant des sessions SSH pour worker2/3/4/5 et en collant la même commande puisque l’on veut que tous soient des nœuds de travail.
Après avoir fait que tous les nœuds de travail rejoignent Swarm, retournez à votre session SSH worker1 et lancez la commande suivante pour vérifier l’état de votre Swarm, c’est-à-dire voir les nœuds qui y participent :
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1ndqsslh7fpquc7fi35leig54 worker4 Ready Active
1qh4aat24nts5izo3cgsboy77 worker5 Ready Active
25nwmw5eg7a5ms4ch93aw0k03 worker3 Ready Active
5oof62fetd4gry7o09jd9e0kf * manager1 Ready Active Leader
5pm9f2pzr8ndijqkkblkgqbsf worker2 Ready Active
9yq4lcmfg0382p39euk8lj9p4 worker1 Ready Active
docker@manager1:~$
Comme prévu, vous pouvez voir qu’il y a 6 nœuds, un en tant que manager (manager1) et les 5 autres en tant que Worker. Vous pouvez également exécuter la commande standard docker info ici et zoomer dans la section Swarm pour vérifier les détails de votre Swarm.
Swarm: active
NodeID: 5oof62fetd4gry7o09jd9e0kf
Is Manager: true
ClusterID: 6z3sqr1aqank2uimyzijzapz3
Managers: 1
Nodes: 6
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Heartbeat Tick: 1
Election Tick: 3
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Node Address: 192.168.1.8
Notez quelques-unes des propriétés :
- Swarm est marqué comme actif. Il a 6 nœuds au total et 1 manager parmi eux.
- Lorsque vous exécutez la commande docker info sur le manager1 lui-même, cela montre que Is Manager comme true.
- La section Raft est l’algorithme de consensus Raft utilisé. Consultez les détails ici.
Créer un service
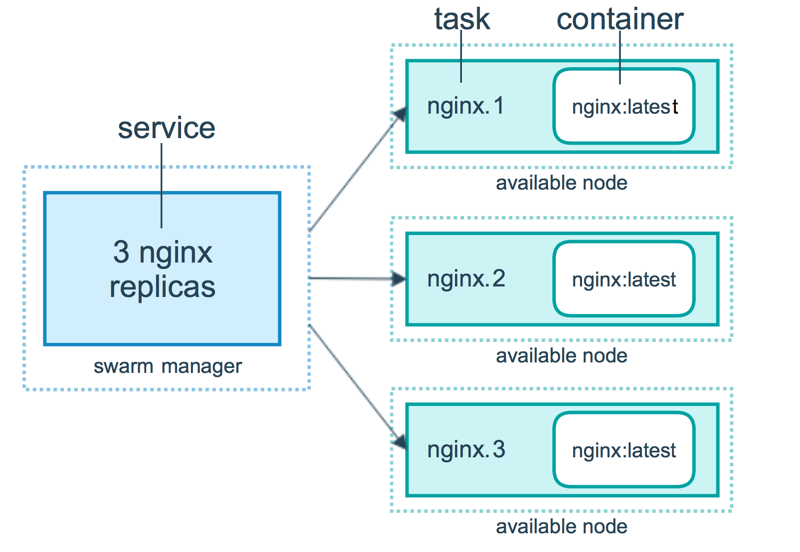
Maintenant que votre swarm est opérationnel, il est temps de planifier vos conteneurs. C’est toute la beauté de la couche d’orchestration. Vous allez vous concentrer sur l’application et ne pas vous soucier de l’endroit où l’application va s’exécuter.
Tout ce que vous allez faire est de dire au manager d’activer les conteneurs pour vous . Il prendra aussi soin de programmer les conteneurs, d’envoyer les commandes aux nœuds et de les distribuer.
Pour démarrer un service, vous devez disposer des éléments suivants :
- Quelle est l’image Docker que vous souhaitez exécuter ? Dans ce cas-ci, vous exécuterez l’image nginx standard qui est officiellement disponible depuis le Docker hub.
- Vous exposerez votre service sur le port 80.
- Vous pouvez spécifier le nombre de conteneurs (ou d’instances) à lancer. Ceci est spécifié via le paramètre des répliques.
- Vous déciderez du nom de votre service. Gardez ça à portée de main.
Ce que vous allez faire ensuite est de lancer 5 répliques du conteneur nginx. Pour ce faire, allez à nouveau dans la session SSH pour votre nœud manager1. Et entrez la commande de création de service docker suivante :
docker service create –replicas 5 -p 80:80 –name web nginxctolq1t4h2o859t69j9pptyye
Ce qui s’est passé, c’est que la couche d’orchestration va maintenant fonctionner.
Vous pouvez connaître l’état du service en donnant la commande suivante :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
ctolq1t4h2o8 web 0/5 nginx
Cela montre que les répliques ne sont pas encore prêtes. Vous devrez entrer cette commande plusieurs fois.
En attendant, vous pouvez également voir l’état du service et comment il est orchestré pour les différents nœuds en utilisant la commande suivante :
docker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Preparing 2 minutes ago
17* web.2 nginx manager1 Running Running 22 seconds ago
ey* web.3 nginx worker2 Running Running 2 minutes ago
bd* web.4 nginx worker5 Running Running 45 seconds ago
dw* web.5 nginx worker4 Running Running 2 minutes ago
Cela montre que les nœuds sont en cours d’installation. Cela pourrait prendre un moment.
Mais, remarquez quelques petites choses. Dans la liste des nœuds ci-dessus, vous pouvez voir que les 5 conteneurs sont planifiés par la couche d’orchestration sur manager1, worker2, worker3, worker4 et worker5. Aucun conteneur n’est prévu pour le nœud worker1et c’est très bien.
Quelques exécutions du service docker ls montrent les réponses suivantes :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
ctolq1t4h2o8 web 3/5 nginx
docker@manager1:~$
et enfin :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
ctolq1t4h2o8 web 5/5 nginx
docker@manager1:~$
Si vous regardez les processus de service à ce stade, vous pouvez voir ce qui suit :
docker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running 4 minutes ago
17* web.2 nginx manager1 Running Running 7 minutes ago
ey* web.3 nginx worker2 Running Running 9 minutes ago
bd* web.4 nginx worker5 Running Running 8 minutes ago
dw* web.5 nginx worker4 Running Running 9 minutes ago
Si vous faites un docker ps sur le nœud manager1 maintenant, vous constaterez que le démon nginx a été lancé.
docker@manager1:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
933309b04630 nginx : latest “nginx -g ‘daemon off” 2 minutes ago Up 2 minutes 80/tcp, 443/tcp web.2.17d502y6qjhd1wqjle13nmjvc
docker@manager1:~$
Accéder au service
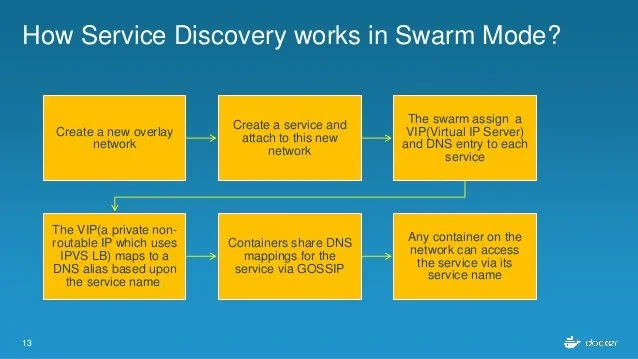
Vous pouvez accéder au service en cliquant sur l’un des nœuds du manager ou du travailleur. Cela n’a pas d’importance si le nœud en particulier n’a pas de conteneur planifié dessus. C’est toute l’idée de Swarm.
Essayez une boucle sur n’importe quelle adresse IP de la machine Docker (manager1 ou worker/2/3/4/5) ou tapez l’URL (https://<machine-ip>) dans le navigateur. Vous devriez être en mesure d’obtenir la page d’accueil NGINX standard.
Ou si vous touchez l’adresse IP du worker.
C’est sympa, n’est-ce pas ?
Idéalement, vous devriez mettre le service Docker Swarm derrière un Load Balancer.
Contrôle de l’évolutivité
Ceci est fait via la commande d’évolutivité de service docker. Il y a actuellement 5 conteneurs en cours d’exécution. Augmentez-le jusqu’à 8 comme indiqué ci-dessous en exécutant la commande sur le nœud manager1.
$ docker service scale web=8
web scaled to 8
Maintenant, vous pouvez vérifier l’état du service et les tâches de processus via les mêmes commandes comme indiqué ci-dessous :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
ctolq1t4h2o8 web 5/8 nginx
Dans la commande ps web ci-dessous, vous trouverez qu’il a décidé de planifier les nouveaux conteneurs sur travailleur1 (2 d’entre eux) et manager1 (l’un d’entre eux)
docker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running 14 minutes ago
17* web.2 nginx manager1 Running Running 17 minutes ago
ey* web.3 nginx worker2 Running Running 19 minutes ago
bd* web.4 nginx worker5 Running Running 17 minutes ago
dw* web.5 nginx worker4 Running Running 19 minutes ago
8t* web.6 nginx worker1 Running Starting about a minute ago
b8* web.7 nginx manager1 Running Ready less than a second ago
0k* web.8 nginx worker1 Running Starting about a minute ago
Vous attendez un moment, puis tout va bien, comme indiqué ci-dessous :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND ctolq1t4h2o8 web 8/8 nginxdocker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running 16 minutes ago
17* web.2 nginx manager1 Running Running 19 minutes ago
ey* web.3 nginx worker2 Running Running 21 minutes ago
bd* web.4 nginx worker5 Running Running 20 minutes ago
dw* web.5 nginx worker4 Running Running 21 minutes ago
8t* web.6 nginx worker1 Running Running 4 minutes ago
b8* web.7 nginx manager1 Running Running 2 minutes ago
0k* web.8 nginx worker1 Running Running 3 minutes agodocker@manager1:~$
Inspecter les nœuds
Vous pouvez inspecter les nœuds à tout moment via la commande d’inspection de nœud.
Par exemple, si vous êtes déjà sur le nœud (par exemple manager1) que vous voulez vérifier, vous pouvez utiliser le nom self pour le nœud.
$ docker node inspect self
Ou si vous voulez vérifier sur les autres nœuds, donnez le nom du nœud. Par exemple :
$ docker node inspect worker1
Drainer un nœud
Si le nœud est ACTIF, il est prêt à accepter des tâches provenant du maître, c’est-à-dire le manager. Par exemple, vous pouvez voir la liste des nœuds et leur statut en entrant la commande suivante sur le nœud manager1.
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1ndqsslh7fpquc7fi35leig54 worker4 Ready Active
1qh4aat24nts5izo3cgsboy77 worker5 Ready Active
25nwmw5eg7a5ms4ch93aw0k03 worker3 Ready Active
5oof62fetd4gry7o09jd9e0kf * manager1 Ready Active Leader
5pm9f2pzr8ndijqkkblkgqbsf worker2 Ready Active
9yq4lcmfg0382p39euk8lj9p4 worker1 Ready Active
docker@manager1:~$
Vous pouvez voir que leur DISPONIBILITÉ est réglée sur PRET.
Selon la documentation, lorsque le nœud est actif, il peut recevoir de nouvelles tâches :
- Au cours d’une mise à jour de service pour intensifier
- Lors d’une mise à jour progressive
- Lorsque vous définissez un autre nœud pour drainer la disponibilité
- Lorsqu’une tâche échoue sur un autre nœud actif
Mais parfois, vous devez mettre le nœud pour une raison de maintenance. Cela signifiait en définissant la Disponibilité sur le mode drain. Essayez cela avec l’un de vos nœuds.
Mais d’abord, vérifiez l’état de vos processus pour les services Web et sur les nœuds qu’ils exécutent :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND ctolq1t4h2o8 web 8/8 nginxdocker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running 54 minutes ago
17* web.2 nginx manager1 Running Running 57 minutes ago
ey* web.3 nginx worker2 Running Running 59 minutes ago
bd* web.4 nginx worker5 Running Running 57 minutes ago
dw* web.5 nginx worker4 Running Running 59 minutes ago
8t* web.6 nginx worker1 Running Running 41 minutes ago
b8* web.7 nginx manager1 Running Running 39 minutes ago
0k* web.8 nginx worker1 Running Running 41 minutes ago
Vous voyez que vous avez 8 répliques de votre service :
- 2 sur manager1
- 2 sur worker1
- 1 chacun sur worker2, worker3. worker4, worker5
Maintenant, utilisez une autre commande pour vérifier ce qui se passe dans le nœud worker1.
docker@manager1:~$ docker node ps worker1
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
8t* web.6 nginx worker1 Running Running 44 minutes ago
0k* web.8 nginx worker1 Running Running 44 minutes
agodocker@manager1:~$
Nous pouvons également utiliser la commande docker d’inspection de nœud pour vérifier la disponibilité du nœud et comme prévu, vous trouverez une section dans la sortie comme suit :
$ docker node inspect worker1
…..”Spec”: {
“Role”: “worker”,
“Availability”: “active”
}, …
Ou
docker@manager1:~$ docker node inspect — pretty worker1
ID: 9yq4lcmfg0382p39euk8lj9p4
Hostname: worker1
Joined at: 2016–09–16 08:32:24.5448505 +0000 utc
Status:
State: Ready
Availability: Active
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 987.2 MiB
Plugins:
Network: bridge, host, null, overlay
Volume: local
Engine Version: 1.12.1
Engine Labels:
— provider = hypervdocker@manager1:~$
Vous pouvez voir qu’il est “Actif” pour son attribut Disponibilité.
Maintenant, définissez la Disponibilité en DRAINER. Lorsque vous entrez cette commande, le manager arrête les tâches s’exécutant sur ce nœud et lance les répliques sur d’autres nœuds avec la disponibilité ACTIVE.
Donc, ce que l’on attend, c’est que le Manager amènera les 2 conteneurs en cours d’exécution sur travailleur1 et les planifie sur les autres nœuds (manager1 ou travailleur2 ou travailleur3 ou travailleur4 ou travailleur5).
Cela se fait en mettant à jour le nœud en définissant sa disponibilité en “drainer”.
docker@manager1:~$ docker node update –availability drain worker1
worker1
Maintenant, si vous faites un état de processus pour le service, vous voyez une sortie intéressante (la sortie a été allégée pour un formatage correct) :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND ctolq1t4h2o8 web 8/8 nginxdocker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running about an hour ago
17* web.2 nginx manager1 Running Running about an hour ago
ey* web.3 nginx worker2 Running Running about an hour ago
bd* web.4 nginx worker5 Running Running about an hour ago
dw* web.5 nginx worker4 Running Running about an hour ago
8t* \_ web.6 nginx worker1 Shutdown Shutdown about a min ago
b8* web.7 nginx manager1 Running Running 49 minutes ago
7a* web.8 nginx worker3 Running Preparing about a min ago
0k* \_ web.8 nginx worker1 Shutdown Shutdown about a min
agodocker@manager1:~$
Vous pouvez voir que les conteneurs sur le worker1 (que vous avez demandé à être drainé) sont reprogrammés sur d’autres travailleurs. Dans le scénario ci-dessus, ils ont été planifiés respectivement sur worker2 et worker3. Ceci est requis, car vous avez demandé que les 8 répliques soient exécutées lors d’un exercice de mise à l’échelle antérieure.
Vous pouvez voir que les deux conteneurs sont toujours à l’état de “Préparation” et après un certain temps si vous exécutez la commande, ils s’exécutent tous comme indiqué ci-dessous :
docker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMAND ctolq1t4h2o8 web 8/8 nginxdocker@manager1:~$ docker service ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
7i* web.1 nginx worker3 Running Running about an hour ago
17* web.2 nginx manager1 Running Running about an hour ago
ey* web.3 nginx worker2 Running Running about an hour ago
bd* web.4 nginx worker5 Running Running about an hour ago
dw* web.5 nginx worker4 Running Running about an hour ago
2u* web.6 nginx worker4 Running Running 8 minutes ago
8t* \_ web.6 nginx worker1 Shutdown Shutdown about 8 min ago
b8* web.7 nginx manager1 Running Running 56 minutes ago
7a* web.8 nginx worker3 Running Preparing about 8 min ago
0k* \_ web.8 nginx worker1 Shutdown Shutdown about 8 min
agodocker@manager1:~$
Cela fait une démo cool, n’est-ce pas ?
Supprimer le service
Vous pouvez simplement utiliser la commande service rm comme indiqué ci-dessous :
docker@manager1:~$ docker service rm web
webdocker@manager1:~$ docker service ls
ID NAME REPLICAS IMAGE COMMANDdocker@manager1:~$ docker service inspect web
[]
Error: no such service: web
Application des mises à jour progressives
C’est simple. Au cas où vous auriez une image Docker mise à jour à déployer vers les nœuds, tout ce que vous devez faire est de lancer une commande de mise à jour de service.
Par exemple :
$ docker service update –image <imagename>:<version> web
Conclusion
La simplicité de Docker Swarm est définitivement impressionnante. Tout comme les commandes de base fournies avec le jeu d’outils Docker standard, il a été judicieux d’introduire les commandes Swarm dans le même jeu d’outils.
Docker Swarm a beaucoup plus à offrir et vous devriez creuser davantage dans la documentation.
Il est difficile de savoir lequel de Kubernetes ou de Swarm ressortira gagnant. En revanche, il ne fait aucun doute que vous devriez comprendre les deux pour voir quelles sont leurs capacités et ensuite prendre une décision.

- 10 Meilleurs robots de trading IA assistés par l’Intelligence Artificielle - 28 mars 2023
- 9 Meilleurs appareils de mesure et détecteurs EMF - 19 mars 2023
- 10 Meilleurs générateurs de visages basés sur IA - 8 mars 2023