
Mis à jours 15 février 2021 Comment les outils de développement accélèrent-ils la livraison de logiciels ?
Devops est en partie une philosophie et en grande partie des outils. Voici comment fonctionnent ces outils avec leurs dévots magiques.
Il était une fois, il y avait un développeur qui avait besoin d’écrire un code sur une base de données. Il a donc demandé à l’administrateur de la base de données (DBA) d’accéder à la base de données de production.
“Oh, mon cher, non”, a déclaré le DBA. “Vous ne pouvez pas utiliser nos données. Vous avez besoin d’obtenir votre propre base de données. Demandez aux opérations. ”
“Oh, mon cher, non”, a déclaré le responsable des opérations. “Nous n’avons pas de licence Oracle de rechange, et il faudrait six mois pour vous l’obtenir et disposer du serveur sur lequel elle sera exécutée. Mais je ferai ce que je peux. ”
Vous pouvez voir où cela se passe. Vous pouvez même entendre “bwahaha” après chaque réponse. Bien sûr, le DBA et le responsable des opérations ne font que leur travail, mais le développeur et les besoins de l’entreprise sont bloqués dans la voie lente.
Et si le développeur a pu générer une machine virtuelle déjà configurée avec des versions d’essai du système d’exploitation correct, une base de données correcte, des schémas de table et d’index corrects ainsi que des données de test valides de façon syntaxique ! Et si tout cela se passait sous le contrôle d’un fichier de configuration et de scripts pendant que le développeur a brassé et a bu une tasse de café ! Quel agile serait-il ?
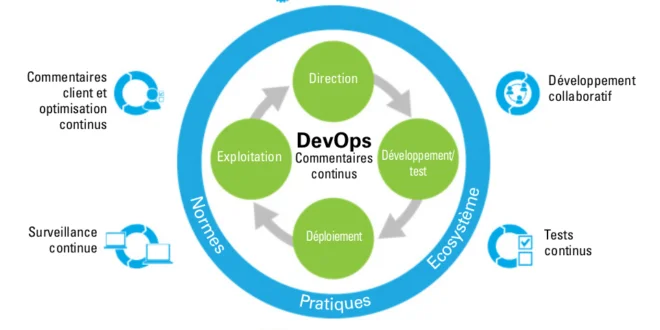
Opter pour devops. Fondamentalement, devops offre une grande boîte d’outils qui automatisent la façon dont les requêtes sont utilisées pour répondre en “non”. Les développeurs obtiennent ce dont ils ont besoin pour faire leur travail, et les opérations peuvent mettre fin à leur négociation sans causer trop de problèmes. Ces outils peuvent être divisés en plusieurs ensembles qui prennent en charge chaque étape du cycle de vie du développement de logiciel, du codage à l’intégration, au déploiement, à la surveillance et aux rapports de bogues.
Outils de développement
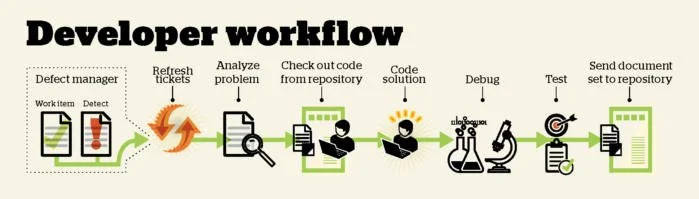
Pour un développeur, la vie professionnelle tourne généralement autour d’un environnement de développement. Cela comporte plusieurs pièces, qui pourraient être intégrées ou pourraient être une sélection d’outils indépendants.
Le code existant vit dans un référentiel tel que Git ou Team Foundation Server (TFS), et la première tâche quotidienne du développeur (après la réunion quotidienne que les organisations agiles tiennent en premier lieu) est de vérifier ou de cloner tout le code d’intérêt du dépôt partagé. Dans un monde idéal, les vérifications ou les poussées effectuées par d’autres personnes auraient un impact sur le code du développeur, car le code de chaque développeur serait déjà fusionné, intégré et testé. Dans le monde réel, ce ne sera pas toujours le cas et les modifications telles que la fusion, l’intégration et le test apportés hier pourraient être une question d’ordre secondaire. Dans un monde idéal, tout code serait parfait.
Dans le monde réel, il n’existe pas de code parfait. Le mieux qu’on peut obtenir est un code qui n’a pas de problèmes connus. Du point de vue du développeur, la recherche des défauts avec un logiciel de suivi de bogues, qu’il s’agisse de Bugzilla, JIRA, Redmine, TFS ou tout autre logiciel de suivi de problèmes ainsi que le traitement de tous les “tickets” (les rapports de bogues ou les répartitions des tâches) sont la prochaine question à l’ordre du jour.
Un IDE tel qu’Eclipse ou Visual Studio traite souvent la gestion de défauts, ou peut-être même il est plus concerné à ce sujet, mais à tout le moins, le développeur dispose d’un onglet de navigateur ouvert pour afficher ses problèmes. Dans ce cas, soit le développeur continuera le projet d’hier, soit il l’affichera et gérera une anomalie de priorité plus élevée s’il y en a une. De la même façon, les IDE s’intègrent étroitement aux dépôts, mais à tout le moins, le développeur dispose d’une console de ligne de commande ouverte pour les check-in et check-outs. Et pour compléter le triangle, les logiciels de suivi de bogues s’intègrent souvent avec les dépôts de code source.

L’éditeur de code est généralement le composant principal d’un IDE. Les meilleurs éditeurs de code à des fins de déploiement vous montrent l’état du dépôt du code que vous examinez afin que vous puissiez réclamer immédiatement si vous trouvez un code source obsolète. Ils actualiseront également votre copie avant que vous introduisiez des conflits de fusion.
Les outils de construction des développeurs dépendent des langages de programmation qu’ils utilisent, mais dans le cas des langages compilés, les développeurs souhaitent pouvoir déclencher des compilations à partir de l’IDE et capturer les erreurs ainsi que les avertissements à des fins d’édition. Il aide également si l’éditeur de code connaît la syntaxe du langage tout en signalant les erreurs pendant le codage en arrière-plan et mettre en surbrillance la syntaxe avec des couleurs pour aider les développeurs à confirmer visuellement, par exemple, si la nomination d’une variable déjà définie est correcte ou non.
Lorsque les développeurs écrivent et testent le code, ils passent souvent la majeure partie de la journée à exécuter un débogueur. Lorsqu’ils sont dans une organisation ayant mis en œuvre les devops, ils ont souvent la chance de déboguer dans un environnement virtualisé reflétant fidèlement l’environnement de production. Sans cela, les développeurs devront peut-être utiliser le code stub pour représenter les actions du serveur ou pour que les bases de données locales soient compatibles avec les bases de données distantes.
Toutefois, les testeurs aident les développeurs à exécuter leurs tests unitaires et tests de régression facilement et régulièrement. Idéalement, le cadre de test s’intègre à l’IDE et à tout dépôt local afin que tout nouveau code puisse être testé immédiatement après l’enregistrement pendant que le développeur essaie de trouver fermement une meilleure idée sur la conception. Les tests du développeur devraient être effectués dans l’environnement d’intégration de code via le référentiel partagé, de même que le code source que le développeur a débogué et testé.
Outils d’intégration de code
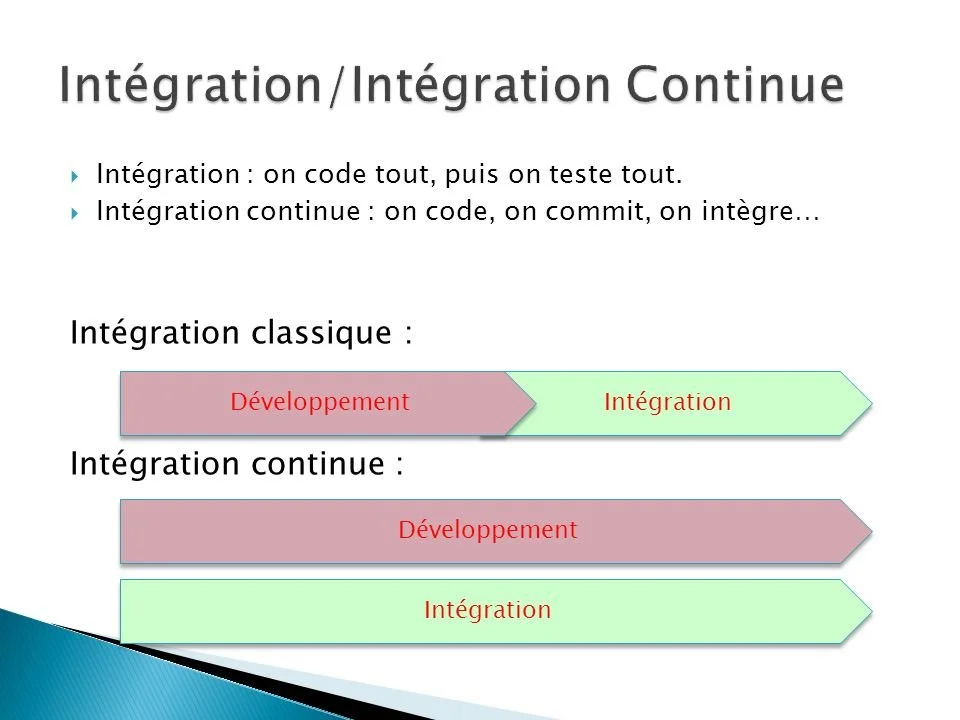
Les outils d’intégration de code prennent le code dans un référentiel partagé, le compilent, le testent et le rapportent sur les résultats. Cela se fait souvent via un serveur d’intégration continue, comme Jenkins, qui le mettra en liaison aux outils de compilation automatisés, aux testeurs automatisés, aux rapports automatisés par courrier électronique et aux logiciels de suivi de problèmes, ainsi qu’aux actions sur le référentiel.
Par exemple, si la compilation réussit et que tous les tests passent, tout le code source actuel et les bibliothèques compilés ainsi que les exécutables peuvent être étiquetés avec le numéro de build actuel dans le référentiel. Si les tests critiques échouent, les enregistrements pertinents peuvent être sauvegardés dans le dépôt partagé et retournés aux développeurs responsables afin qu’ils puissent résoudre les bogues.
Certains projets mettent en œuvre une intégration continue pour chaque poussée de code si le temps de compilation incrémentale est faible. Dans d’autres projets, un retard de temps est introduit après une poussée de code pour que plusieurs poussées puissent être combinées dans la prochaine compilation. La plupart des projets, qu’ils utilisent ou non des compilations et des tests automatiques, qu’ils intègrent ou non après que le code pousse ou sur demande tout au long de la journée, ils exécutent également et quotidiennement des compilations et des tests « propres » souvent dans des environnements de test fraîchement provisionnés.
Outils et environnements de déploiement

Si le serveur d’intégration continue est configuré pour déployer les agents de build, après avoir passé tous les tests, il dépend souvent d’outils de gestion de configuration et de déploiement de logiciels. Ceux-ci varient souvent en fonction de la plate-forme d’exécution et de l’infrastructure supplémentaire.
Par contre, certains outils de gestion de configuration tels qu’Ansible, Chef, Puppet, Salt et Vagrant fonctionnent sur un large éventail de plate-formes en utilisant des langages largement supportés. Notons qu’Ansible et Salt sont des systèmes basés sur Python tandis que Chef, Puppet et Vagrant sont basés sur Ruby.
Ansible est exprimé en YAML et gère les nœuds sur SSH. Chef utilise un langage spécifique au domaine Ruby pour la base de ses configurations, également un serveur Erlang et un client Ruby.
Puppet utilise un langage déclaratif personnalisé pour décrire la configuration du système et utilise habituellement une architecture agent / maître pour la configuration des systèmes, mais il peut également s’exécuter dans une architecture autonome. Il existe plus de 2 500 modules prédéfinis répertoriés dans son dépôt ou Puppet Forge.
Salt, un outil de gestion de serveurs à distance au début, s’est transformé en une application de gestion de configuration de cloud-agnostique et d’exécution à distance. C’est un logiciel open source récompensé plusieurs fois. Salt peut gérer et déployer des systèmes Linux, Unix, Windows et MacOS, et il peut organiser les ressources dans de nombreux clouds. Vagrant est un outil de gestion de configuration spécialisé pour les environnements de développement. Il est considéré comme un wrapper pour VirtualBox, VMware et d’autres gestionnaires de machines virtuelles. Vagrant diminue la reproduction de bogues dépendants de la configuration.
PaaS (plate-forme en tant que service) occupe une place intéressante dans l’écosystème de cloud. Il s’agit principalement d’une plate-forme de développement, de test et de déploiement qui s’ajoute à l’IaaS (infrastructure en tant que service). PaaS peut être déployé sur les sites ou offert en tant que service par un fournisseur de cloud public. Par exemple, le Pivotal Cloud Foundry PaaS peut être déployé sur les sites en complément de la version de VMware d’un cloud privé, ou il peut s’exécuter dans un cloud public IaaS tel qu’Amazon EC2.
Il existe deux types de machines virtuelles : les machines virtuelles exécutant tous les systèmes d’exploitation telles que VMware, et les machines virtuelles exécutant les programmes informatiques telles que Java Virtual Machine. Pour utiliser les outils de déploiement, ce qui est intéressant ce sont les machines virtuelles exécutant les systèmes dans lesquelles on peut déployer PaaS telles que Cloud Foundry ou une application serveur telles que PostgreSQL. À leur tour, les machines virtuelles peuvent être déployées sur un matériel de serveur dédié, sur le site ou hors site, ou sur un cloud IaaS. Les machines virtuelles exécutant le système offrent une excellente isolation de logiciels au détriment d’encourir certains frais généraux d’hyperviseur assez importants et d’utiliser beaucoup de RAM. Divers hyperviseurs et infrastructures IaaS offrent différentes quantités d’isolement de charge et des algorithmes différents pour allouer l’excès de capacité du processeur aux machines virtuelles qui en ont besoin.
Les conteneurs de logiciels tels que Docker offrent une isolation de logiciel assez bonne dans la plupart des cas, avec beaucoup moins de frais généraux que les machines virtuelles. De plus, tous les systèmes PaaS exécutent les applications dans des conteneurs de logiciels. Par exemple, OpenShift utilisé pour exécuter des applications dans des conteneurs appelés engrenages, et utilise SELinux pour l’isolation des engrenages. Aujourd’hui, il utilise Docker comme son format de conteneur et son exécution. De même, Cloud Foundry l’a utilisé pour exécuter des applications dans des conteneurs Warden Linux, mais a introduit un nouveau système de gestion de conteneurs appelé Diego qui supporte Docker et d’autres conteneurs conformes à la spécification Open Container Initiative.
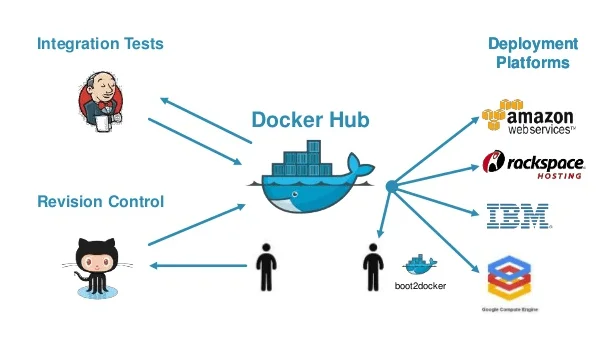
D’autre part, Docker peut fonctionner indépendamment des systèmes PaaS et peut considérablement simplifier le déploiement pour les développeurs. Docker peut faire de multiples clouds comme une grande machine, et peut être utilisé pour l’automatisation des builds, l’intégration continue, les tests et les autres tâches. Alors que Docker a commencé comme une solution unique à Linux, il a récemment bénéficié de l’aide pour Windows.
Dans le grand schéma du cycle de vie d’un logiciel, chaque fonctionnalité passe du design au développement, au test, à la pré-production jusqu’à la production, tandis que les rapports de bogues retournent aux développeurs pour le triage et les résolutions d’anomalies à chaque étape. Pour les produits qui sont publiés chaque année, le passage d’une étape à une autre peut être un processus manuel. Pour les produits agiles qui sont publiés chaque semaine ou deux fois par semaine, la gestion des publications est souvent automatisée. Une partie de ce qui doit être automatisé est la gestion des processus de publication. En outre, les équipes doivent automatiser leurs processus de tests, de suivi des bogues, de compilation, d’emballage, de configuration et de promotion.
Outils de surveillance de l’exécution
Les tests d’acceptation pour les produits comprennent généralement des tests de performance qui peuvent aller jusqu’au test complet de charge avec des profils d’utilisateurs réalistes. Cependant, les performances de l’application peuvent changer dans la production pour plusieurs raisons : un pic d’utilisation, une fuite de mémoire qui se manifeste au fil du temps, une mauvaise position sur un disque, un serveur surchargé ou un index de base de données mal considéré qui ralentit les mises à jour après que sa table sous-jacente devienne grande.
La surveillance de la performance de l’application est donc destinée à créer continuellement des mesures pour les indicateurs clés de performance qui donnent de l’importance à votre application. Ceux-ci sont habituellement répartis en mesures d’utilisateurs comme c’est le moment de consulter une page ou de compléter une transaction, et en mesures du système telles que l’utilisation de la CPU et de la mémoire. Les mesures du système sont généralement disponibles tout le temps. Par contre, les mesures des utilisateurs passifs, souvent collectées à l’aide des appareils de surveillance du réseau, sont très utiles lorsque l’application est fortement utilisée ; et les mesures des utilisateurs actifs, collectées en générant des demandes d’application et en mesurant les temps de réponse, sont souvent réservées aux périodes en dehors des périodes de charge de grande demande.
Lorsque votre application ne fonctionne pas comme vous le souhaitez, déterminer la cause principale peut être un processus frustrant et long. Jusqu’à récemment, les agents DDCM (surveillance des composants de plongée profonde) sont destinés à vous aider à analyser les causes fondamentales cependant, ils génèrent trop de frais généraux pour être utilisés dans la production. De ce fait, vous devriez les utiliser pendant une courte période pour essayer de trouver le problème, puis les stopper afin de permettre à la production de reprendre à pleine capacité. Au cours des dernières années, les nouveaux produits DDCM sur le marché prétend pouvoir surveiller un large éventail de langages et de cadres avec des frais généraux minimes tout en rationalisant le processus d’analyse des sources du problème.
Outils de rapports et de reproduction de bogues
Les outils de gestion de suivi de problèmes jouent un rôle important dans la recherche et le reporting des bogues. Dans le meilleur des cas, une anomalie signalée sera accompagnée d’une description détaillée, d’une cause fondamentale, d’un script afin de reproduire le problème et sera assigné au développeur le plus familier à ce sujet avec le code concerné. Dans le pire des cas, un rapport de bogue provient d’un utilisateur frustré faisant appel au support technique et comprend une conversation du genre :
Support technique : Qu’est-ce qui ne va pas ?
Utilisateur : Il s’est cassé.
Support technique : Que faisiez-vous ?
Utilisateur : Ce que je faisais toujours. Hier, cela a fonctionné.
Support technique : Avez-vous changé quelque chose depuis hier ?
Utilisateur : Je n’ai rien changé.
Inutile de dire que de tels rapports nécessitent une certaine compétence de la part du support technique pour dégager une description et des étapes suffisantes pour reproduire le problème afin de permettre au développeur d’en apporter une solution. Le support technique peut également demander l’entrée et l’exécution à distance de diagnostics sur la machine de l’utilisateur.
Parfois, de tels problèmes ne se reproduiront pas sur la machine d’un développeur. Une raison commune pour cela est que la boîte de développement est trop rapide et dispose trop de mémoire pour montrer le problème. Une autre possibilité est que le développeur possède une bibliothèque installée que l’utilisateur n’en a pas. Et une troisième raison est que l’utilisateur dispose d’une autre application installée qui interfère avec la vôtre.
Une fois que l’environnement d’exécution de l’utilisateur est déterminé, le développeur peut utiliser des outils de gestion de configuration pour créer un environnement d’exécution similaire dans une machine virtuelle. Vagrant, en particulier, est destiné à ces fins. Le test sur machine virtuelle peut être exécuté localement sur la machine du développeur, sur un serveur ou sur un cloud IaaS.
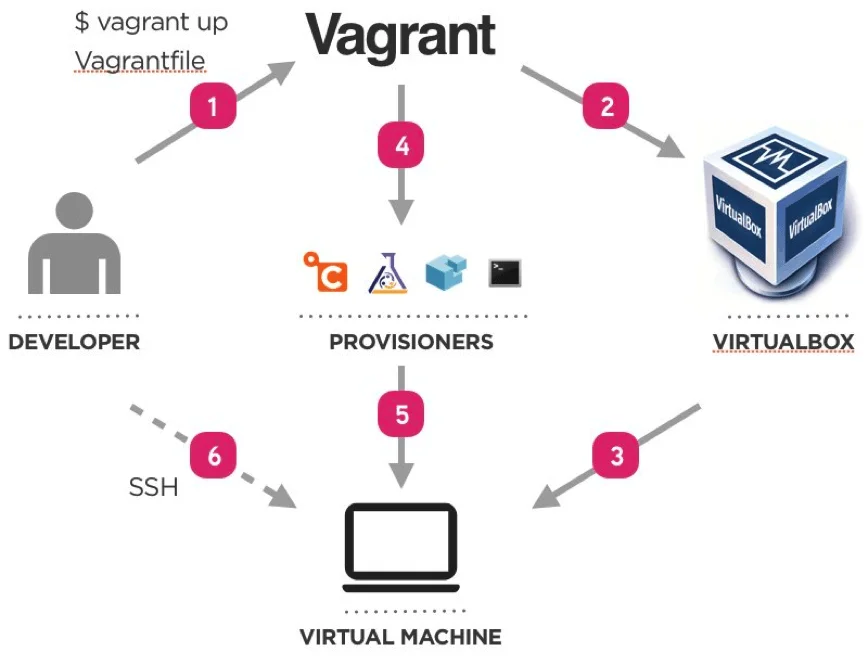
Dans certains cas, les étapes pour reproduire le problème de l’utilisateur changeraient la base de données de production. Dans ces situations, il est important d’obtenir une copie réduite de production de l’application exécutée dans un PaaS, de sorte que les modifications ne se propagent jamais jusqu’à l’environnement de production.
Une fois qu’une résolution au problème est établie et qu’un ensemble de modifications est apporté au référentiel du code, l’application révisée doit être testée au moins par régression, et de préférence tous les tests d’acceptation devront être exécutés. Si le changement est accepté, le gestionnaire de publication ou le gestionnaire de service à la clientèle doit décider de propager le changement à la production ou de le programmer pour une intégration ultérieure et de donner à l’utilisateur une section de code pour corriger une bogue dont un patch ou une solution temporaire et opérationnelle apportée à une bogue.
Le cercle sans fin
Si le cycle de vie de l’application moderne et agile ressemble un peu à la vision d’Ezekiel d’un chariot comportant des roues à l’intérieur d’autres roues, c’est BON : ça l’est. Un ensemble de roues représente les sprints, généralement une à deux semaines, après quoi une version d’application est présentée du développement au test. Un autre ensemble de roues représente la montée d’un build donné, du développement au test, à la pré-production jusqu’à la production. Un ensemble de roues intérieur représente le cycle de vie d’une carte d’histoire ou d’une fonction d’application. Et les roues les plus petites représentent les rapports de bogues et les corrections.
Dans cet environnement compliqué, les magasins de développement peuvent facilement s’enliser à n’importe quel stade. Le but de devops est surtout de voir que les choses de routine telles que l’élaboration du nettoyage d’un test de la base de données ou la promotion d’un build sont rapides et faciles afin que les développeurs puissent se concentrer sur la compilation de fonctionnalités réelles et la résolution de véritables bogues.

- 10 Meilleurs robots de trading IA assistés par l’Intelligence Artificielle - 28 mars 2023
- 9 Meilleurs appareils de mesure et détecteurs EMF - 19 mars 2023
- 10 Meilleurs générateurs de visages basés sur IA - 8 mars 2023



